Monitoring
Overview
This document provides an overview of topics related to RabbitMQ monitoring. Monitoring RabbitMQ and applications that use it is critically important. Monitoring helps detect issues before they affect the rest of the environment and, eventually, the end users.
The combination of Prometheus and Grafana is the highly recommended option for RabbitMQ monitoring.
Monitoring is a broad topic. This guide covers several :
- What is monitoring, why it is important, what common approaches to it exist
- Available monitoring options:
- Prometheus-compatible external scrapers for production clusters
- Kubernetes Operator monitoring features for Kubernetes users
- interactive command line tool for focused troubleshooting
- management plugin's HTTP API for development environments
- What infrastructure and kernel metrics are important to monitor
- What RabbitMQ metrics are available:
- How much overhead does monitoring introduce and how frequently should monitoring checks be performed?
- Application-level metrics
- How to approach node health checking and why it's more involved than a single CLI command
- Health checks use as node readiness probes during deployment or upgrades
- Log aggregation across all nodes and applications is closely related to monitoring
A number of popular tools, both open source and commercial, can be used to monitor RabbitMQ. As mentioned above, the combination of Prometheus and Grafana is what team RabbitMQ would recommend to most users. On Kubernetes, the Prometheus plugin is automatically enabled by the Kubernetes RabbitMQ Operator.
What is Monitoring?
In this guide we define monitoring as a process of capturing the behaviour of a system via health checks and metrics over time. This helps detect anomalies: when the system is unavailable, experiences an unusual load, exhausted of certain resources or otherwise does not behave within its normal (expected) parameters. Monitoring involves collecting and storing metrics for the long term, which is important for more than anomaly detection but also root cause analysis, trend detection and capacity planning.
Monitoring systems typically integrate with alerting systems. When an anomaly is detected by a monitoring system an alarm of some sort is typically passed to an alerting system, which notifies interested parties such as the technical operations team.
Having monitoring in place means that important deviations in system behavior, from degraded service in some areas to complete unavailability, is easier to detect and the root cause takes much less time to find. Operating a distributed system without monitoring data is a bit like trying to get out of a forest without a GPS navigator device or compass. It doesn't matter how brilliant or experienced the person is, having relevant information is very important for a good outcome.
Health Checks' Role in Monitoring
Health checks are another important aspect of monitoring. A health check involves a command or set of commands that collect a few essential metrics of the monitored system over time and assert on the state (health) of the system based on that metric.
For example, whether RabbitMQ's Erlang VM is running is one such check. The metric in this case is "is an OS process running?". The normal operating parameters are "the process must be running". Finally, there is an evaluation step.
Of course, there are more varieties of health checks. Which ones are most appropriate depends on the definition of a "healthy node" used. So, it is a system- and team-specific decision. RabbitMQ CLI tools provide commands that can serve as useful health checks. They will be covered later in this guide.
While health checks are a useful tool, they only provide so much insight into the state of the system because they are by design focused on one or a handful of metrics, usually check a single node and can only reason about the state of that node at a particular moment in time. For a more comprehensive assessment, collect more metrics over time. This detects more types of anomalies as some can only be identified over longer periods of time. This is usually done by tools known as monitoring tools of which there are a grand variety. This guides covers some tools used for RabbitMQ monitoring.
System and RabbitMQ Metrics
Some metrics are RabbitMQ-specific: they are collected and reported by RabbitMQ nodes. In this guide we refer to them as "RabbitMQ metrics". Examples include the number of socket descriptors used, total number of enqueued messages or inter-node communication traffic rates. Others metrics are collected and reported by the OS kernel. Such metrics are often called system metrics or infrastructure metrics. System metrics are not specific to RabbitMQ. Examples include CPU utilisation rate, amount of memory used by processes, network packet loss rate, et cetera. Both types are important to track. Individual metrics are not always useful but when analysed together, they can provide a more complete insight into the state of the system. Then operators can form a hypothesis about what's going on and needs addressing.
Infrastructure and Kernel Metrics
First step towards a useful monitoring system starts with infrastructure and kernel metrics. There are quite a few of them but some are more important than others. Collect the following metrics on all hosts that run RabbitMQ nodes or applications:
- CPU stats (user, system, iowait, idle percentages)
- Memory usage (used, buffered, cached and free percentages)
- Kernel page cache, in particular in clusters where streams are used
- Virtual Memory statistics (dirty page flushes, writeback volume)
- Disk I/O (frequency of operations, amount of data transferred per unit time, statistical distribution of long I/O operation take to completes, I/O operation failure rates)
- Free disk space on the mount used for the node data directory
- File descriptors used by
beam.smpvs. max system limit - TCP connections by state (
ESTABLISHED,CLOSE_WAIT,TIME_WAIT) - Network throughput (bytes received, bytes sent) & maximum network throughput
- Network latency (between all RabbitMQ nodes in a cluster as well as to/from clients)
There is no shortage of existing tools (such as Prometheus or Datadog) that collect infrastructure and kernel metrics, store and visualise them over periods of time.
Monitoring with Prometheus-compatible Tools
RabbitMQ comes with a built-in plugin that exposes metrics in the Prometheus format: rabbitmq_prometheus.
The plugin expose a number of RabbitMQ metrics for nodes, connections, queues, message rates and so on.
This plugin has low overhead and is highly recommended for production environments.
Prometheus in combination with Grafana or the ELK stack have a number of benefits compared to other monitoring options:
- Decoupling of the monitoring system from the system being monitored
- Lower overhead
- Long term metric storage
- Access to additional related metrics such as those of the runtime
- More powerful and customizable user interface
- Ease of metric data sharing: both metric state and dashboards
- Metric access permissions are not specific to RabbitMQ
- Collection and aggregation of node-specific metrics which is more resilient to individual node failures
How to Enable It
To enable the Prometheus plugin, use
rabbitmq-plugins enable rabbitmq_prometheus
or pre-configure the plugin.
HTTP API Endpoint
The plugin serves metrics to Prometheus-compatible scrapers on port 15692 by default:
curl {hostname}:15692/metrics
Please consult the Prometheus plugin guide to learn more.
Monitoring using Management Plugin
The built-in management plugin can also collect metrics and display them in the UI. This is a convenient option for development environments.
The plugin can also serve metrics to monitoring tools. It has, however, a number of significant limitations compared to monitoring with Prometheus:
- The monitoring system is intertwined with the system being monitored
- Monitoring using management plugin tends to have more overhead, in partiicular to node RAM footprint
- It only stores recent data (think hours, not days or months)
- It only has a basic user interface
- Its design emphasizes ease of use over best possible availability.
- Management UI access is controlled via the RabbitMQ permission tags system (or a convention on JWT token scopes)
How to Enable It
To enable the management plugin, use
rabbitmq-plugins enable rabbitmq_management
or pre-configure the plugin.
HTTP API Endpoint
The plugin serves metrics via the HTTP API on port 15672 by default and uses Basic HTTP Authentication:
curl -u {username}:{password} {hostname}:15672/api/overview
Please consult the Management plugin guide to learn more.
Monitoring of Kubernetes Operator-deployed Clusters
RabbitMQ clusters deployed to Kubernetes using the RabbitMQ Kubernetes Operator can be monitored with Prometheus or compatible tools.
This is covered in a dedicated guide on Monitoring RabbitMQ in Kubernetes.
Interactive Command Line-Based Observer Tool
rabbitmq-diagnostics observer is a command-line tool similar to top, htop, vmstat. It is a command line
alternative to Erlang's Observer application. It provides
access to many metrics, including detailed state of individual runtime processes:
- Runtime version information
- CPU and schedule stats
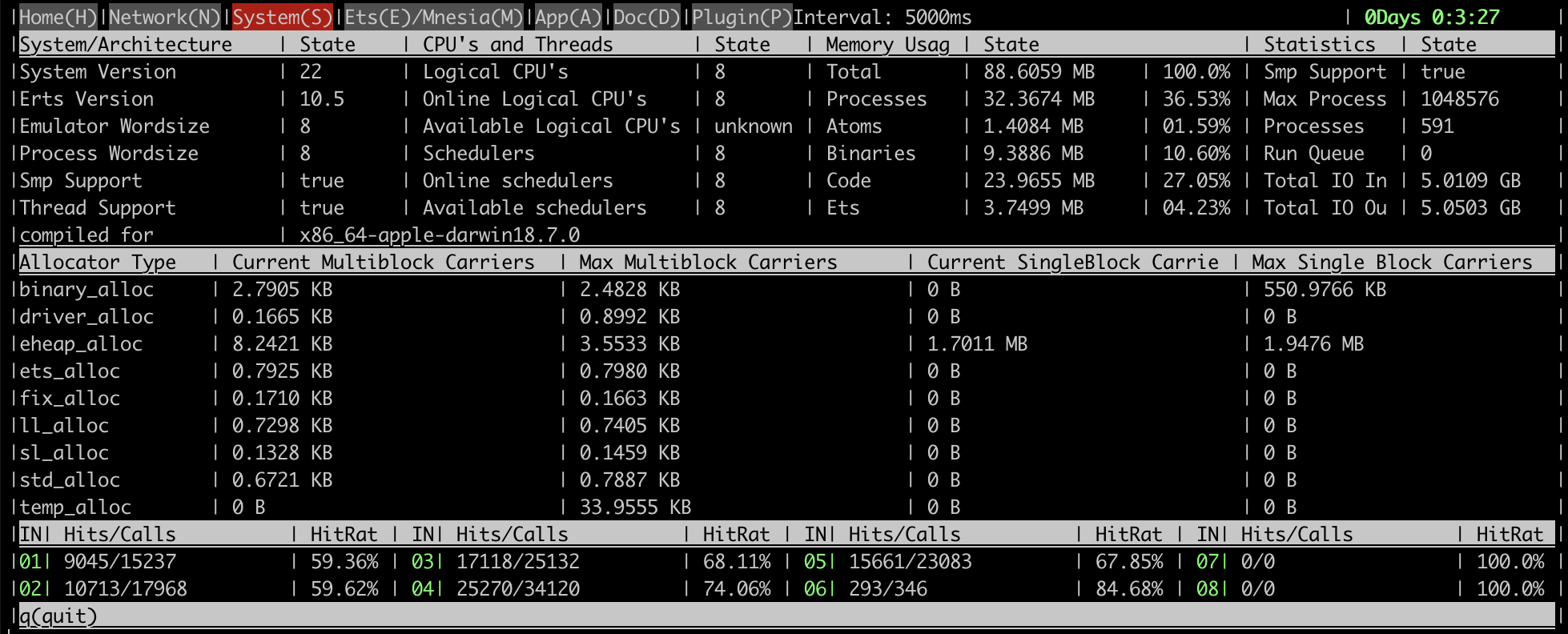
- Memory allocation and usage stats
- Top processes by CPU (reductions) and memory usage
- Network link stats
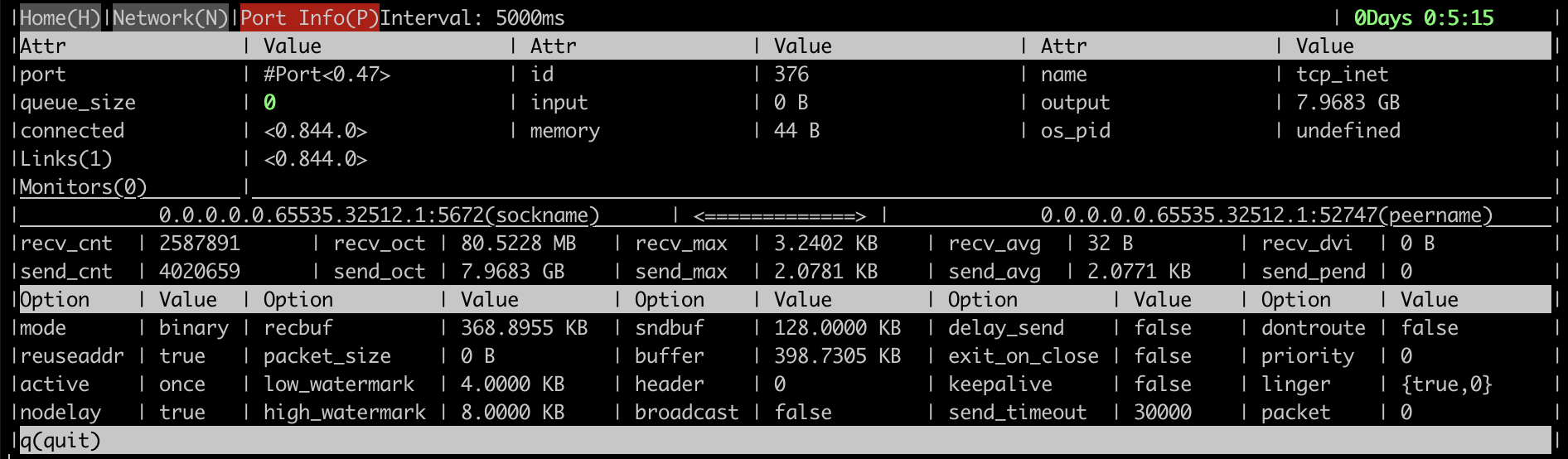
- Detailed process information such as basic TCP socket stats
and more, in an interactive ncurses-like command line interface with periodic updates.
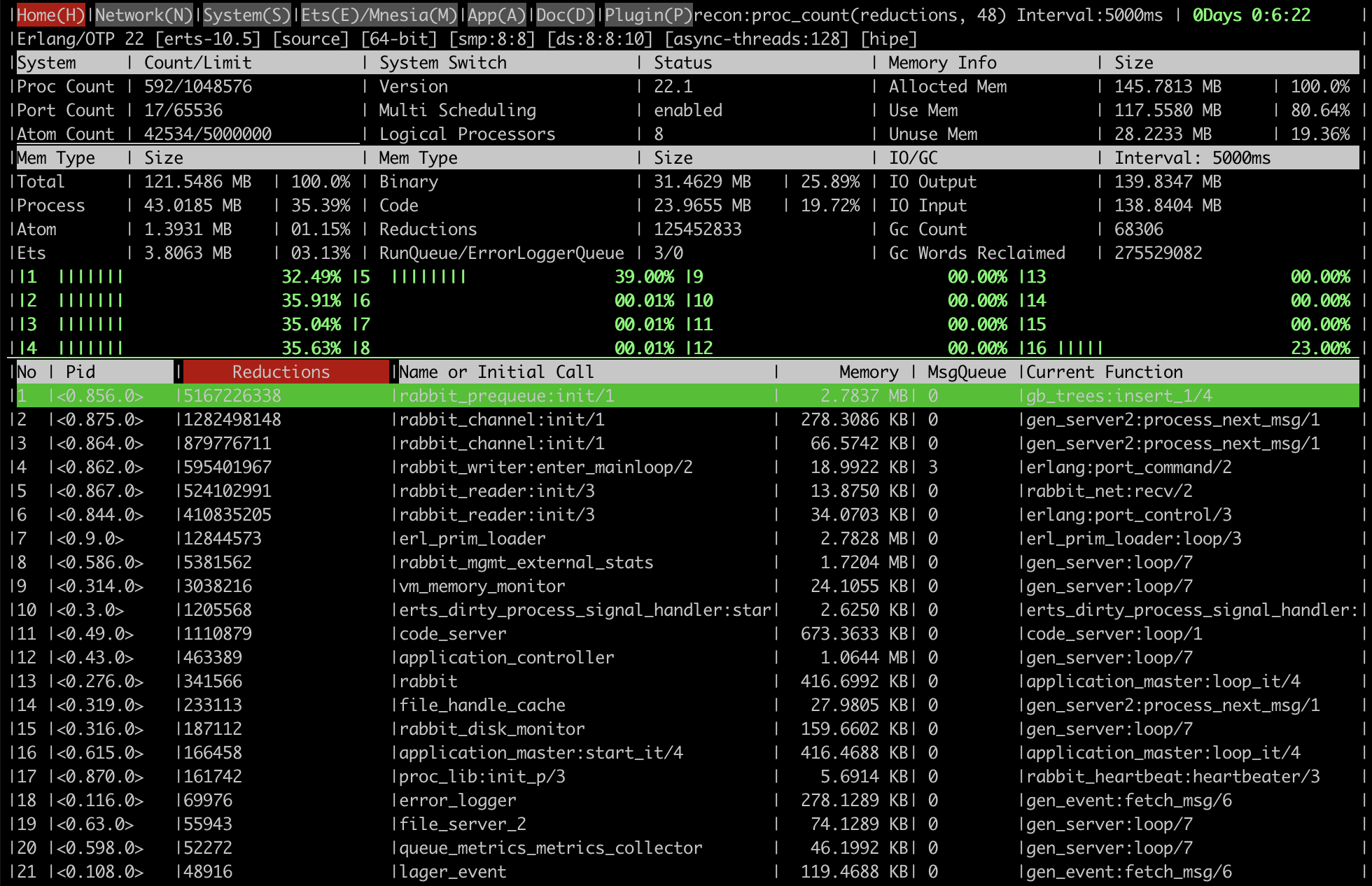
Here are some screenshots that demonstrate what kind of information the tool provides.
An overview page with key runtime metrics:
Memory allocator stats:
A client connection process metrics:
Resource Use and Overhead of Monitoring
Monitoring can be intrusive and increase load on the system being monitored. This depends on how many entities (connections, queues, etc) there are in the monitored cluster but also on other factors: monitoring frequency, how much data monitoring tools request, and so on.
Many monitoring systems poll their monitored services periodically. How often that's done varies from tool to tool but usually can be configured by the operator.
Very frequent polling can have negative consequences on the system under monitoring. For example, excessive load balancer checks that open a test TCP connection to a node can lead to a high connection churn. Excessive checks of channels and queues in RabbitMQ will increase its CPU consumption. When there are many (say, 10s of thousands) of them on a node, the difference can be significant.
Another common issue with monitoring tools is how much data they request from RabbitMQ nodes. Some monitoring tools query a full page or all queues just to get a single metric value of one queue. This can significantly increase CPU load footprint of monitoring.
Such conditions can be identified using the rabbitmq_top plugin or rabbitmq-diagnostics observer.
Top processes by the number of reductions (a unit of runtime scheduler time) will usually be one
of the following processes:
rabbit_mgmt_db_cache_connectionsrabbit_mgmt_external_statsqueue_metrics_metrics_collector- and other processes whose names end with a
_metrics_collector
To reduce monitoring footprint, reduce frequency of monitoring and make sure that the monitoring tool only queries for the data it needs.
Frequency of Monitoring
The recommended metric collection interval for production is 30 seconds, or another suitable value in the 30 to 60 second range. Prometheus exporter API is designed to be scraped every 15 to 30 seconds, including production systems.
In a development environment, to collect at an interval which is closer to real-time, use 5 seconds —- but not lower!
For rate metrics, use a time range that spans four or more metric collection intervals so that it can tolerate race-conditions and is resilient to scrape failures.
RabbitMQ Metrics
This section will cover multiple RabbitMQ-specific aspects of monitoring. Most metrics mentioned in this section are exposed by both the Prometheus plugin and management UI.
Cluster-wide Metrics
Cluster-wide metrics provide a high level view of cluster state. Some of them describe interaction between nodes. Examples of such metrics are cluster link traffic and detected network partitions. Others combine metrics across all cluster members. A complete list of connections to all nodes would be one example. Both types are complimentary to infrastructure and node metrics.
GET /api/overview is the HTTP API endpoint that returns cluster-wide metrics.
| Metric | JSON field name |
| Cluster name | cluster_name |
| Cluster-wide message rates | message_stats |
| Total number of connections | object_totals.connections |
| Total number of channels | object_totals.channels |
| Total number of queues | object_totals.queues |
| Total number of consumers | object_totals.consumers |
| Total number of messages (ready plus unacknowledged) | queue_totals.messages |
| Number of messages ready for delivery | queue_totals.messages_ready |
| Number of unacknowledged messages | queue_totals.messages_unacknowledged |
| Messages published recently | message_stats.publish |
| Message publish rate | message_stats.publish_details.rate |
| Messages delivered to consumers recently | message_stats.deliver_get |
| Message delivery rate | message_stats.deliver_get_details.rate |
| Other message stats |
|
Node Metrics
There are two HTTP API endpoints that provide access to node-specific metrics:
GET /api/nodes/{node}returns stats for a single nodeGET /api/nodesreturns stats for all cluster members
The latter endpoint returns an array of objects. Monitoring tools that support (or can support) that as an input should prefer that endpoint since it reduces the number of requests. When that's not the case, use the former endpoint to retrieve stats for every cluster member in turn. That implies that the monitoring system is aware of the list of cluster members.
Most of the metrics represent point-in-time absolute values. Some, represent activity over a recent period of time (for example, GC runs and bytes reclaimed). The latter metrics are most useful when compared to their previous values and historical mean/percentile values.
| Metric | JSON field name |
| Total amount of memory used | mem_used |
| Memory usage high watermark | mem_limit |
| Is a memory alarm in effect? | mem_alarm |
| Free disk space low watermark | disk_free_limit |
| Is a disk alarm in effect? | disk_free_alarm |
| File descriptors available | fd_total |
| File descriptors used | fd_used |
| File descriptor open attempts | io_file_handle_open_attempt_count |
| Inter-node communication links | cluster_links |
| GC runs | gc_num |
| Bytes reclaimed by GC | gc_bytes_reclaimed |
| Erlang process limit | proc_total |
| Erlang processes used | proc_used |
| Runtime run queue | run_queue |
Individual Queue Metrics
Individual queue metrics are made available through the HTTP API
via the GET /api/queues/{vhost}/{qname} endpoint.
The table below lists some key metrics that can be useful for monitoring queue state. Some other metrics (such as queue state and "idle period") should be considered internal metrics used by RabbitMQ contributors.
| Metric | JSON field name |
| Memory | memory |
| Total number of messages (ready plus unacknowledged) | messages |
| Number of messages ready for delivery | messages_ready |
| Number of unacknowledged messages | messages_unacknowledged |
| Messages published recently | message_stats.publish |
| Message publishing rate | message_stats.publish_details.rate |
| Messages delivered recently | message_stats.deliver_get |
| Message delivery rate | message_stats.deliver_get_details.rate |
| Other message stats |
|
Application-level Metrics
A system that uses messaging is almost always distributed. In such systems it is often not immediately obvious which component is misbehaving. Every single part of the system, including applications, should be monitored and investigated.
Some infrastructure-level and RabbitMQ metrics can show presence of an unusual system behaviour or issue but can't pinpoint the root cause. For example, it is easy to tell that a node is running out of disk space but not always easy to tell why. This is where application metrics come in: they can help identify a run-away publisher, a repeatedly failing consumer, a consumer that cannot keep up with the rate, or even a downstream service that's experiencing a slowdown (e.g. a missing index in a database used by the consumers).
Some client libraries and frameworks provide means of registering metrics collectors or collect metrics out of the box. RabbitMQ Java client, Spring AMQP, and NServiceBus are some examples. With others developers have to track metrics in their application code.
What metrics applications track can be system-specific but some are relevant to most systems:
- Connection opening rate
- Channel opening rate
- Connection failure (recovery) rate
- Publishing rate
- Delivery rate
- Positive delivery acknowledgement rate
- Negative delivery acknowledgement rate
- Mean/95th percentile delivery processing latency
Health Checks
A health check is a command that tests whether an aspect of the RabbitMQ service is operating as expected. Health checks are executed periodically by machines or interactively by operators.
Health checks can be used to both assess the state and liveness of a node but also as readiness probes by deployment automation and orchestration tools, including during upgrades.
There are a series of health checks that can be performed, starting with the most basic and very rarely producing false positives, to increasingly more comprehensive, intrusive, and opinionated that have a higher probability of false positives. In other words, the more comprehensive a health check is, the less conclusive the result will be.
Health checks can verify the state of an individual node (node health checks), or the entire cluster (cluster health checks).
Individual Node Checks
This section covers several examples of node health check. They are organised in stages. Higher stages perform more comprehensive and opinionated checks. Such checks will have a higher probability of false positives. Some stages have dedicated RabbitMQ CLI tool commands, others can involve extra tools.
While the health checks are ordered, a higher number does not mean a check is "better".
The health checks can be used selectively and combined. Unless noted otherwise, the checks should follow the same monitoring frequency recommendation as metric collection.
Earlier versions of RabbitMQ used an intrusive health check that has since been deprecated and should be avoided. Use one of the checks covered in this section (or their combination).
Stage 1
The most basic check ensures that the runtime is running and (indirectly) that CLI tools can authenticate with it.
Except for the CLI tool authentication
part, the probability of false positives can be considered approaching 0
except for upgrades and maintenance windows.
rabbitmq-diagnostics ping performs this check:
rabbitmq-diagnostics -q ping
# => Ping succeeded if exit code is 0
Stage 2
A slightly more comprehensive check is executing rabbitmq-diagnostics status status:
This includes the stage 1 check plus retrieves some essential system information which is useful for other checks and should always be available if RabbitMQ is running on the node (see below).
rabbitmq-diagnostics -q status
# => [output elided for brevity]
This is a common way of confidence checking a node.
The probability of false positives can be considered approaching 0
except for upgrades and maintenance windows.
Stage 3
Includes previous checks and also verifies that the RabbitMQ application is running
(not stopped with rabbitmqctl stop_app
or the Pause Minority partition handling strategy)
and there are no resource alarms.
# lists alarms in effect across the cluster, if any
rabbitmq-diagnostics -q alarms
rabbitmq-diagnostics check_running is a check that makes sure that the runtime is running
and the RabbitMQ application on it is not stopped or paused.
rabbitmq-diagnostics check_local_alarms checks that there are no local alarms in effect
on the node. If there are any, it will exit with a non-zero status.
The two commands in combination deliver the stage 3 check:
rabbitmq-diagnostics -q check_running && rabbitmq-diagnostics -q check_local_alarms
# if both checks succeed, the exit code will be 0
The probability of false positives is low. Systems hovering around their high runtime memory watermark will have a high probability of false positives. During upgrades and maintenance windows can raise significantly.
Specifically for memory alarms, the GET /api/nodes/{node}/memory HTTP API endpoint can be used for additional checks.
In the following example its output is piped to jq:
curl --silent -u guest:guest -X GET http://127.0.0.1:15672/api/nodes/rabbit@hostname/memory | jq
# => {
# => "memory": {
# => "connection_readers": 24100480,
# => "connection_writers": 1452000,
# => "connection_channels": 3924000,
# => "connection_other": 79830276,
# => "queue_procs": 17642024,
# => "plugins": 63119396,
# => "other_proc": 18043684,
# => "metrics": 7272108,
# => "mgmt_db": 21422904,
# => "mnesia": 1650072,
# => "other_ets": 5368160,
# => "binary": 4933624,
# => "msg_index": 31632,
# => "code": 24006696,
# => "atom": 1172689,
# => "other_system": 26788975,
# => "allocated_unused": 82315584,
# => "reserved_unallocated": 0,
# => "strategy": "rss",
# => "total": {
# => "erlang": 300758720,
# => "rss": 342409216,
# => "allocated": 383074304
# => }
# => }
# => }
The breakdown information it produces can be reduced down to a single value using jq or similar tools:
curl --silent -u guest:guest -X GET http://127.0.0.1:15672/api/nodes/rabbit@hostname/memory | jq ".memory.total.allocated"
# => 397365248
rabbitmq-diagnostics -q memory_breakdown provides access to the same per category data
and supports various units:
rabbitmq-diagnostics -q memory_breakdown --unit "MB"
# => connection_other: 50.18 mb (22.1%)
# => allocated_unused: 43.7058 mb (19.25%)
# => other_proc: 26.1082 mb (11.5%)
# => other_system: 26.0714 mb (11.48%)
# => connection_readers: 22.34 mb (9.84%)
# => code: 20.4311 mb (9.0%)
# => queue_procs: 17.687 mb (7.79%)
# => other_ets: 4.3429 mb (1.91%)
# => connection_writers: 4.068 mb (1.79%)
# => connection_channels: 4.012 mb (1.77%)
# => metrics: 3.3802 mb (1.49%)
# => binary: 1.992 mb (0.88%)
# => mnesia: 1.6292 mb (0.72%)
# => atom: 1.0826 mb (0.48%)
# => msg_index: 0.0317 mb (0.01%)
# => plugins: 0.0119 mb (0.01%)
# => mgmt_db: 0.0 mb (0.0%)
# => reserved_unallocated: 0.0 mb (0.0%)
Stage 4
Includes all checks in stage 3 plus a check on all enabled listeners (using a temporary TCP connection).
To inspect all listeners enabled on a node, use rabbitmq-diagnostics listeners:
rabbitmq-diagnostics -q listeners --node rabbit@target-hostname
# => Interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
# => Interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
# => Interface: [::], port: 5671, protocol: amqp/ssl, purpose: AMQP 0-9-1 and AMQP 1.0 over TLS
# => Interface: [::], port: 15672, protocol: http, purpose: HTTP API
# => Interface: [::], port: 15671, protocol: https, purpose: HTTP API over TLS (HTTPS)
rabbitmq-diagnostics check_port_connectivity [--address <address>] is a command that
performs the basic TCP connectivity check mentioned above:
# This check will try to open a TCP connection to the discovered listener ports.
# Since nodes can be configured to listen to specific interfaces, an --address should
# be provided, or CLI tools will have to rely on the configured hostname resolver to know where to connect.
rabbitmq-diagnostics -q check_port_connectivity --node rabbit@target-hostname --address <ip-address-to-connect-to>
# If the check succeeds, the exit code will be 0
The probability of false positives is generally low but during upgrades and maintenance windows can raise significantly.
Stage 5
Includes all checks in stage 4 plus checks that there are no failed virtual hosts.
rabbitmq-diagnostics check_virtual_hosts is a command
checks whether any virtual host dependencies may have failed. This is done for all
virtual hosts.
rabbitmq-diagnostics -q check_virtual_hosts --node rabbit@target-hostname
# if the check succeeded, exit code will be 0
The probability of false positives is generally low except for systems that are under high CPU load.
Health Checks as Readiness Probes
In some environments, node restarts are controlled with a designated health check.
The checks verify that one node has started and the deployment process can proceed to the next one.
If the check does not pass, the deployment of the node is considered to be incomplete and the deployment process
will typically wait and retry for a period of time. One popular example of such environment is Kubernetes
where an operator-defined readiness probe
can prevent a deployment from proceeding when the OrderedReady pod management policy
is used (which is not recommended to use with RabbitMQ!) or when a rolling restart is performed.
Given the peer syncing behavior during node restarts, such a health check can prevent a cluster-wide restart from completing in time. Checks that explicitly or implicitly assume a fully booted node that's rejoined its cluster peers will fail and block further node deployments.
Moreover, most CLI commands (such as rabbitmq-diagnostics) has a performance impact because the CLI joins the Erlang
distribution (the same mechanism used for clustering RabbitMQ nodes).
Joining and leaving this cluster on every probe execution has unnecessary overhead.
RabbitMQ Kubernetes Operator configures a TCP port check on the AMQP port
as the readinessProbe and defines no livenessProbe at all. This should be considered the best practice.
Monitoring of Clusters
Monitoring a single node is easy and straightforward.
When monitoring clusters it is important to understand the guarantees provided by API endpoints used. In a clustered environment every node can serve metric endpoint requests. In addition, some metrics are node-specific while others are cluster-wide.
Every node provides access to node-specific metrics for itself. Like with infrastructure and OS metrics, node-specific metrics must be collected for each cluster node.
Prometheus and management plugin API endpoints have important differences when it comes to what metrics they serve and how cluster-wide metrics are aggregated.
Prometheus
With the Prometheus pluginm every node provides access to node-specific metrics.
Prometheus queries the metric endpoint, {hostname}:15692/metrics, and stores the results.
Cluster-wide metrics are then computed from this node-specific data.
Management Plugin
With management plugin, every node provides access to node-specific metrics for itself as well as other cluster nodes.
Cluster-wide metrics can be fetched from any node that can contact its peers. That node will collect and combine data from its peers as needed before producing a response.
With management plugin, inter-node connectivity issues will affect HTTP API behaviour. Choose a random online node for monitoring requests. For example, using a load balancer or round-robin DNS.
Deprecated Health Checks and Monitoring Features
Legacy Intrusive Health Check
Earlier versions of RabbitMQ provided a single opinionated and intrusive health check command (and its respective HTTP API endpoint):
# DO NOT USE: this health check is long deprecated and in modern versions it is a no-op
rabbitmq-diagnostics node_health_check
The above command is deprecated will be removed in a future version of RabbitMQ and is to be avoided. Systems that use it should adopt one of the fine grained modern health checks instead.
The above check forced every connection, queue leader replica, and channel in the system to emit certain metrics. With a large number of concurrent connections and queues, this can be very resource-intensive and too likely to produce false positives.
The above check is also not suitable to be used as a readiness probe as it implicitly assumes a fully booted node.
Monitoring Tools
The following is an alphabetised list of third-party tools commonly used to collect RabbitMQ metrics. These tools vary in capabilities but usually can collect both infrastructure-level and RabbitMQ metrics.
Note that this list is by no means complete.
| Monitoring Tool | Online Resource(s) |
| AppDynamics | |
| AWS CloudWatch | GitHub |
| collectd | GitHub |
| DataDog | |
| Dynatrace | Dynatrace RabbitMQ monitoring |
| Ganglia | GitHub |
| Graphite | Tools that work with Graphite |
| Munin | |
| Nagios | GitHub |
| Nastel AutoPilot | Nastel RabbitMQ Solutions |
| New Relic | New Relic RabbitMQ monitoring |
| Prometheus | |
| Sematext | Sematext RabbitMQ monitoring integration, Sematext RabbitMQ logs integration |
| Zabbix | Zabbix by HTTP, Zabbix by Agent, Blog article |
| Zenoss |
Log Aggregation
Logs are also very important in troubleshooting a distributed system. Like metrics, logs can provide important clues that will help identify the root cause. Collect logs from all RabbitMQ nodes as well as all applications (if possible).